Customer Success Doesn't Need Opus
9 models, 4 skills, 3 runs each — Gemini 3.1 Pro won, Opus came last
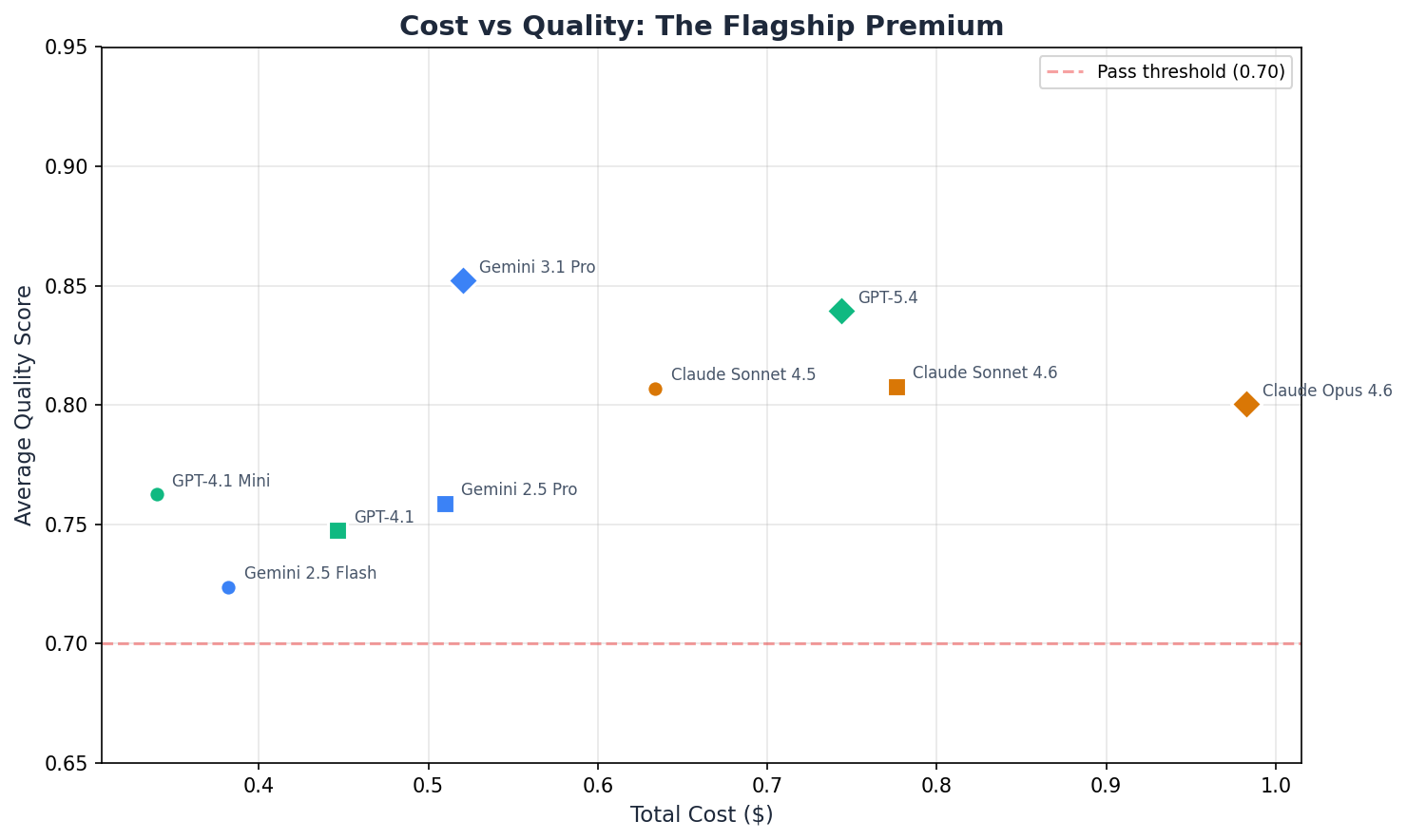
The most expensive model scored the lowest. Across four customer success tasks, nine models, and three providers — each tested three times for statistical confidence — Claude Opus 4.6 averaged 0.80 ± 0.01. Gemini 3.1 Pro averaged 0.85 ± 0.01 at roughly half the per-call cost. GPT-4.1 Mini averaged 0.76 ± 0.03 at a fraction of the flagship price.
This is the first post in a benchmark series testing AI models on real enterprise department workflows. Every number comes with a confidence interval.
What We Tested
Four skills that map to what customer success teams actually do, day in, day out.
Ticket Triage
Ten support tickets classified by severity, SLA, routing team, and priority order. Output validated against a human-written golden answer covering all 10 tickets.
Complaint Response
Enterprise VP escalation about three outages in one quarter. Model drafts customer email and internal notes. Judged on tone, SLA acknowledgment, and policy adherence.
Knowledge Base Generation
Raw Slack messages and Jira notes about API key rotation turned into a structured help article. Tests nested-section reasoning and FAQ coverage.
Churn Risk Analysis
A $156K enterprise account with 97 days until renewal. Model produces risk assessment, contributing factors, and retention recommendations. Text-mode eval.
Ticket triage validates structured classification — severity, SLA, routing, priority order. Complaint response tests tone-aware drafting with policy boundaries. Knowledge base generation exercises nested structural reasoning over messy input. Churn analysis is the one open-ended, analytical task (scored in text mode with an anchored judge rather than structured field checks).
How We Judged
Nine models across three tiers per provider, each tested three times for statistical confidence.
| Tier | Anthropic | OpenAI | |
|---|---|---|---|
| Flagship | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
| Mid | Claude Sonnet 4.6 | GPT-4.1 | Gemini 2.5 Pro |
| Light | Claude Sonnet 4.5 | GPT-4.1 Mini | Gemini 2.5 Flash |
Three-layer evaluation
Each output is scored through three independent layers:
- Rules-based checks (free, deterministic): regex pattern matching for required structural elements — ticket IDs, severity levels, routing destinations, risk scores.
- Golden answer validation (free, deterministic): field-by-field comparison against human-written reference answers. Each golden carries provenance metadata. Scoring uses configurable thresholds — 20% tolerance for numeric values, set overlap for lists, case-insensitive exact match for enums.
- Ensemble LLM judge with provider recusal: Claude Opus, GPT-5.4, and Gemini 3.1 Pro each score independently, but never their own provider's outputs. When scoring a Claude model, only GPT and Gemini judge. Scores combined via median. Judges are anchored to the golden answer.
This three-layer approach means: rules catch structural failures, golden answers catch factual errors, and the judge catches semantic quality issues. No single layer can inflate a score.
Recommendation Matrix
For each skill and provider, the recommended model is the cheapest tier that scores within 0.05 of its own flagship.
| Skill | Anthropic Pick | OpenAI Pick | Google Pick |
|---|---|---|---|
| Ticket Triage | Sonnet 4.5 (0.84) * | GPT-4.1 Mini (0.88) * | Gemini 2.5 Pro (0.89) * |
| Complaint Response | Sonnet 4.5 (0.76) * | GPT-5.4 (0.82) | Gemini 2.5 Pro (0.72) * |
| Knowledge Base | Sonnet 4.5 (0.78) * | GPT-4.1 (0.76) * | Gemini 3.1 Pro (0.83) |
| Churn Analysis | Sonnet 4.5 (0.85) * | GPT-4.1 Mini (0.83) * | Gemini 2.5 Flash (0.85) * |
* = flagship is overkill (cheaper model matches quality within 0.05).
Ten out of twelve combinations suggest flagship is overkill — though as noted in Limitations, some of these rest on gaps near the 0.05 threshold and should be read as directional. The two clear flagship wins: GPT-5.4 on complaint response (0.82 vs 0.72 for Mini — a 0.10 gap well beyond noise) and Gemini 3.1 Pro on knowledge base (0.83 vs 0.59 for Flash — Flash genuinely struggles with complex nested article structure).
Full Results
| Model | Avg Score | Pass Rate | Total Cost | Avg Tokens |
|---|---|---|---|---|
| Gemini 3.1 Pro | 0.852 | 4/4 | $0.521 | — |
| GPT-5.4 | 0.839 | 4/4 | $0.744 | — |
| Claude Sonnet 4.6 | 0.808 | 4/4 | $0.776 | — |
| Claude Sonnet 4.5 | 0.807 | 4/4 | $0.634 | — |
| Claude Opus 4.6 | 0.800 | 4/4 | $0.983 | — |
| Gemini 2.5 Pro | 0.759 | 3/4 | $0.510 | — |
| GPT-4.1 | 0.748 | 3/4 | $0.446 | — |
| GPT-4.1 Mini | 0.763 | 3/4 | $0.340 | — |
| Gemini 2.5 Flash | 0.724 | 3/4 | $0.382 | — |
Skill-by-Skill Breakdown
| Skill | Claude Opus 4.6 | Claude Sonnet 4.6 | Claude Sonnet 4.5 | GPT-5.4 | GPT-4.1 | GPT-4.1 Mini | Gemini 3.1 Pro | Gemini 2.5 Pro | Gemini 2.5 Flash |
|---|---|---|---|---|---|---|---|---|---|
| Ticket Triage | 0.84 | 0.91 | 0.84 | 0.89 | 0.65 | 0.88 | 0.92 | 0.89 | 0.75 |
| Complaint Response | 0.76 | 0.76 | 0.76 | 0.82 | 0.74 | 0.72 | 0.77 | 0.72 | 0.71 |
| Knowledge Base | 0.75 | 0.72 | 0.78 | 0.80 | 0.76 | 0.62 | 0.83 | 0.58 | 0.59 |
| Churn Analysis | 0.85 | 0.83 | 0.85 | 0.84 | 0.84 | 0.83 | 0.90 | 0.84 | 0.85 |
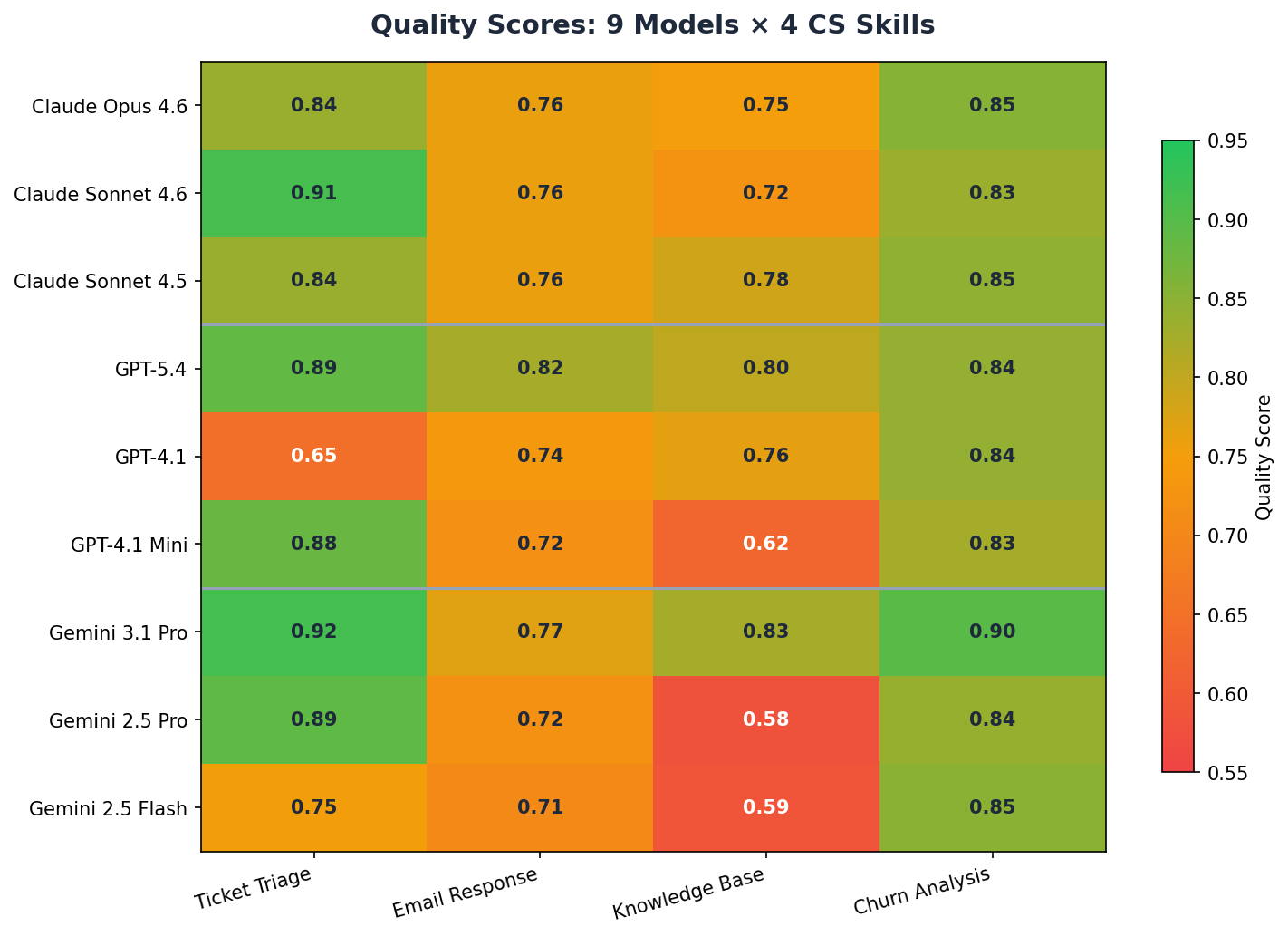
Four patterns stand out.
First, Gemini 3.1 Pro is the best overall model at 0.85 average — not GPT-5.4 (0.84) and definitely not Opus (0.80). It delivers better quality at roughly half the per-call cost of Opus.
Second, Anthropic's tiers are roughly equivalent on CS tasks. Sonnet 4.5 (Light, 0.81), Sonnet 4.6 (Mid, 0.81), and Opus (Flagship, 0.80) all land within 0.01 of each other — well within noise at N=3. The flagship premium buys no measurable improvement on these workflows.
Third, knowledge base generation separates the tiers. It's the only skill where light models genuinely struggle. GPT-4.1 Mini scores 0.62, Gemini 2.5 Flash scores 0.59 — both below the 0.70 pass threshold. The nested structure (sections with headings, troubleshooting with issue/solution pairs, FAQ with question/answer) requires sustained structural reasoning that cheaper models can't maintain.
Fourth, latency varies 3x across providers. GPT-4.1 Mini averages 15 seconds per call, Gemini 3.1 Pro averages 39 seconds, and Anthropic models range from 45–55 seconds. For real-time CS workflows, this latency gap matters as much as quality.
Tier Gaps — How Much Does Cheaper Cost You?
| Provider | Flagship | Mid | Light | Gap to Light |
|---|---|---|---|---|
| Anthropic | 0.800 | 0.808 | 0.807 | −0.007 |
| OpenAI | 0.839 | 0.747 | 0.763 | 0.077 |
| 0.852 | 0.759 | 0.724 | 0.128 |
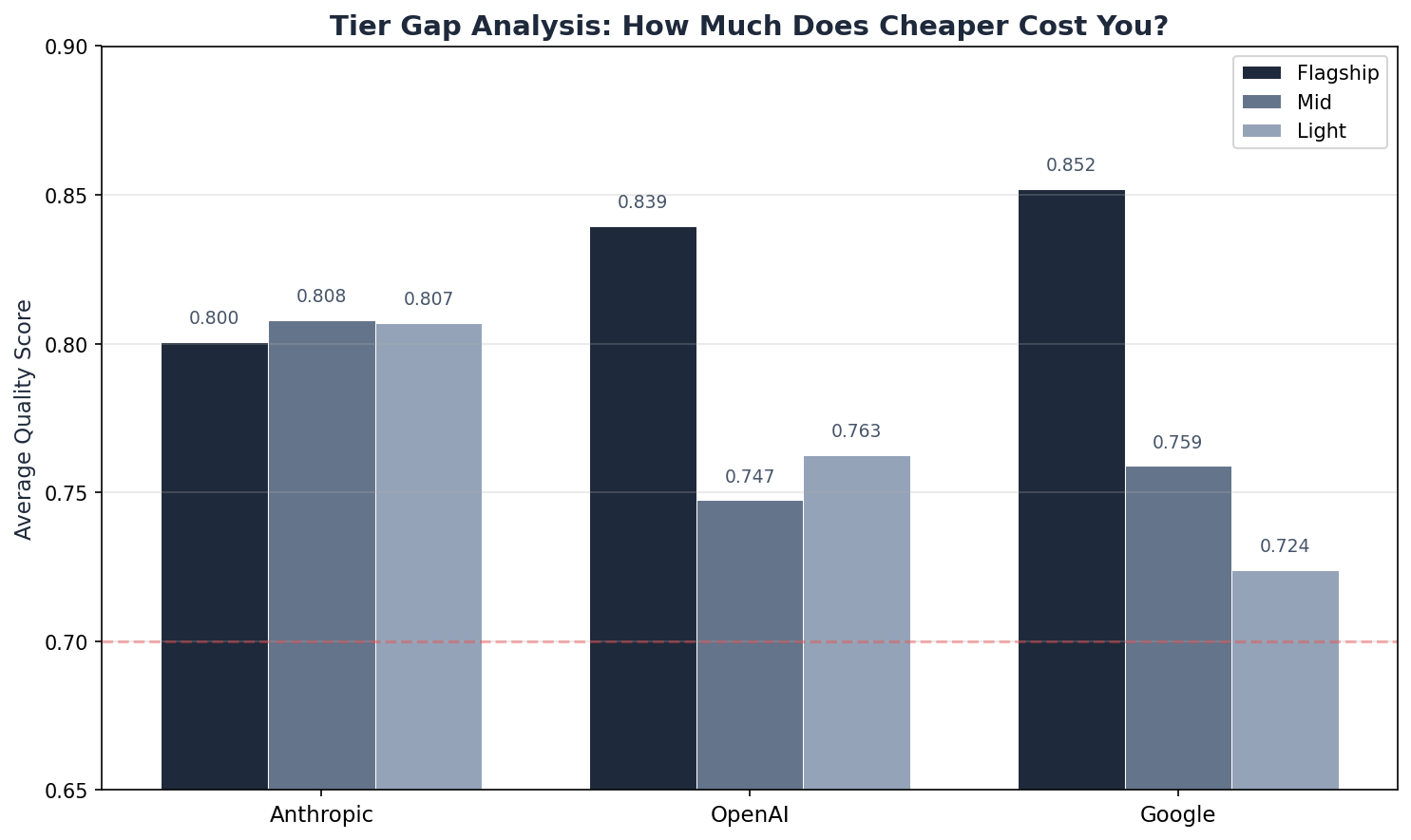
Anthropic's gap is effectively zero — all three tiers score within 0.01. The flagship premium buys no measurable improvement for CS tasks.
OpenAI degrades gracefully (0.077 gap), staying above the pass threshold at every tier.
Google has the widest gap (0.128) — Gemini 2.5 Flash drops significantly on knowledge base, pulling the average down. But Gemini 3.1 Pro at the top is the benchmark's best model.
Cost Efficiency
| Model | Tier | Avg Score | Total Cost | Cost / Quality Pt |
|---|---|---|---|---|
| Gemini 3.1 Pro | Flagship | 0.852 | $0.521 | $0.61 |
| GPT-5.4 | Flagship | 0.839 | $0.744 | $0.89 |
| Claude Sonnet 4.6 | Mid | 0.808 | $0.776 | $0.96 |
| Claude Sonnet 4.5 | Light | 0.807 | $0.634 | $0.79 |
| Claude Opus 4.6 | Flagship | 0.800 | $0.983 | $1.23 |
| Gemini 2.5 Pro | Mid | 0.759 | $0.510 | $0.67 |
| GPT-4.1 | Mid | 0.748 | $0.446 | $0.60 |
| GPT-4.1 Mini | Light | 0.763 | $0.340 | $0.45 |
| Gemini 2.5 Flash | Light | 0.724 | $0.382 | $0.53 |
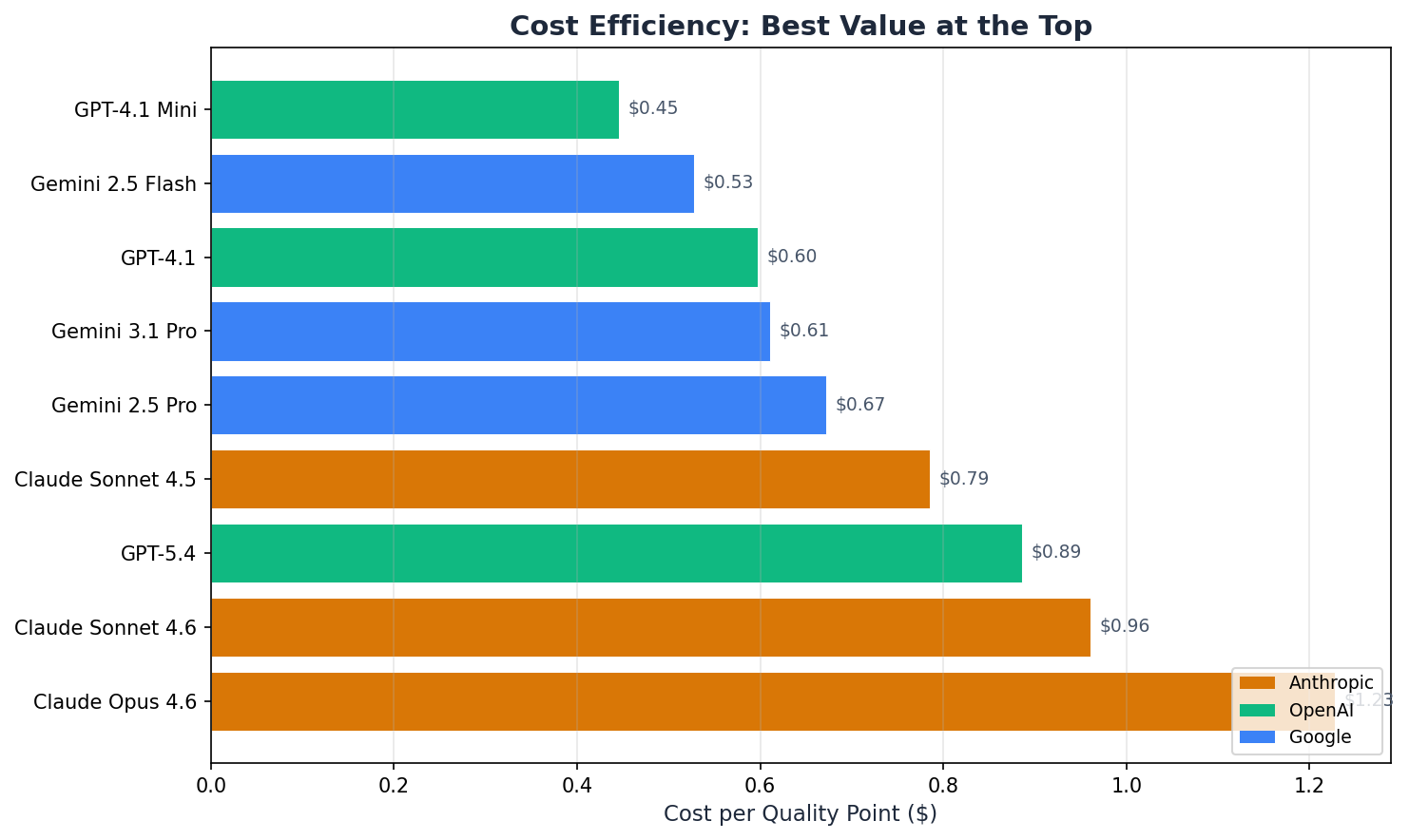
Gemini 3.1 Pro at rank 4 is the sweet spot — highest quality (0.852) at $0.61 per quality point, scoring higher than every other model at a lower cost per quality point than any other flagship.
Claude Opus at $1.23 per quality point is 2.7x more expensive than GPT-4.1 Mini per unit of quality — and produces a smaller unit.
A caveat on this metric: cost efficiency rewards cheap-and-adequate over expensive-and-excellent. GPT-4.1 Mini ranks #1 but averages 0.763 — and fails knowledge base generation outright (0.62). Cost per quality point is only meaningful above your organization's acceptable quality floor, and that floor depends on the task.
What This Means
The question for customer success leaders isn't which model is best. The data answers that: Gemini 3.1 Pro for quality, GPT-4.1 Mini for value. The question is whether model selection decisions in their organizations are being made with benchmark data or with whatever the sales team's demo used.
Anthropic's three tiers produce statistically indistinguishable CS quality (0.80–0.81), but Opus costs 55% more per call than Sonnet 4.5 and responds no faster. If you're using Opus for CS workflows, there's no measurable benefit over the light tier.
The one exception is knowledge base generation, where structural complexity genuinely separates the tiers. If your CS team generates structured documentation with nested sections, troubleshooting guides, and FAQs, the flagship models (Gemini Pro, GPT-5.4) earn their price. For everything else — ticket triage, email drafting, churn analysis — the cheapest models handle it.
Limitations
- Single annotator for golden answers is the largest source of systematic bias. One person wrote the reference answers that anchor scoring. Deterministic checks (rules + golden answer validation) account for ~60% of each skill's weight, and the LLM judge is also anchored to the golden answer. If the annotator systematically undervalues a capability — say, nuanced tone modulation in complaint emails — every model's score shifts accordingly. Inter-annotator agreement is standard in NLP evaluation; we plan to add a second annotator in future runs.
- N=3 limits statistical resolution. With typical stddev of ~0.02, the 95% confidence interval is roughly ±0.023. Differences under 0.02 (e.g., the Anthropic tier spread of 0.007) are noise. Gaps of 0.05 — the threshold used in the recommendation matrix — sit at the edge of statistical significance at this sample size. Some "flagship is overkill" findings rest on borderline gaps and should be read as directional, not definitive.
- Synthetic test data. The tickets, escalation emails, Slack messages, and account data are authored, not pulled from a production system. Real enterprise data has misspellings, mixed languages, screenshots, attachments, and domain-specific jargon. Clean, well-structured inputs may systematically advantage different models than messy production data would.
- Single prompt template per skill. Each model received the same prompt. Flagship models may benefit disproportionately from more detailed prompts, chain-of-thought instructions, or structured output formats. This benchmark tests out-of-the-box performance on a standardized task, not the ceiling with optimized prompting.