Three Frontier Models, Five Agentic Coding Skills
Opus 4.7, GPT-5.4, Gemini 3.1 Pro — all three at 100% pass rate. The real story is cost and tool efficiency.
Three frontier models — Anthropic's Claude Opus 4.7, OpenAI's GPT-5.4, Google's Gemini 3.1 Pro — tested on five agentic software-engineering skills, each with N=3 runs, in an environment that looks like a real repository: a git history, an AGENTS.md file declaring project conventions, unrelated TODOs, stale README sections, legacy tests. Each model had a sandboxed shell to run the test suite and iterate. All three models pass every skill at 100%.
The headline "who wins" answer is boring. All three are capable. The interesting findings are cost, tool-loop efficiency, and one methodological save that caught what would have been a misleading publication — documented in detail below.
The Five Skills — Chosen, Not Curated
Five skills across five orthogonal axes of agentic software-engineering capability. Each axis maps to a published benchmark or vendor-marketing claim that the frontier tier is demonstrably sensitive to. No skill is a toy — each was authored to exercise a specific capability and validated through a smoke pass on all three models before the full benchmark fired.
Fix Cross-File Bug
A bug whose root cause is in module A but whose visible symptoms surface in module B. The model has to trace the call graph across files — single-file patches will still fail the test suite. Tests multi-file debugging discipline. Public analog: SWE-bench Pro.
Fix Concurrency Bug
A multi-threaded scraper with a subtle race condition that only surfaces under load. Passing the test suite once is not enough — the fix has to hold under repeated runs. Tests whether the model recognizes timing-sensitive patterns rather than pattern-matching on a superficial fix. Public analog: Opus 4.7's own "race conditions previous models couldn't resolve" claim.
Multi-Step Migration
Add a new column to a User model end-to-end: SQL migration, model class, database helpers, route handlers. A partial fix (column added but model not updated) still fails. Tests coordinated multi-file planning across the full stack. Public analog: Anthropic "hours-long workflows"; OpenAI OSWorld.
Fix Broken Build
A webapp where server.py imports from a module that does not exist — the build fails on top-level import. Trivial when you run the tests and read the error; impossible when you don't. Tests whether the model uses the test suite as a diagnostic tool or just reads the code and guesses. Public analog: Terminal-Bench 2.0.
Review & Fix Security
A webapp with three OWASP-class vulnerabilities: SQL injection via f-string query, XSS via unescaped template rendering, and a hardcoded secret key. Each has a canonical mitigation (parameterized queries, html.escape, os.environ.get). Tests whether the model recognizes the OWASP pattern and applies the standard fix rather than an ad-hoc workaround.
Why these five, and not others. The public-benchmark landscape has a problem: SWE-bench Verified is near-saturated (Opus 4.7 at 87.6%, Gemini at 80.6%) and Anthropic's own engineering blog flags training-data contamination on it. HumanEval is too short-horizon and nearly universally saturated. We need skills where the top three models legitimately diverge — not noise, but actual capability or efficiency differences.
Each skill here was selected to target a specific axis where vendor claims and public evidence suggest meaningful divergence:
- fix-cross-file-bug — the multi-file-debug axis. Maps to SWE-bench Pro, where GPT-5.4 publicly claims competitive scores. Tests whether a model chases symptoms or finds the root cause when the bug spans module boundaries.
- fix-concurrency-bug — the hard-single-file axis. Maps to Anthropic's Opus 4.7 release-day claim that their model "detected race conditions previous models couldn't resolve." Tests whether the model recognizes timing-sensitive bugs that don't surface on a single test run.
- multi-step-migration — the long-horizon agentic axis. Maps to Anthropic's "hours-long workflows" and OpenAI's OSWorld. Tests coordinated planning across four files: a migration, a model class, database helpers, and route handlers. Partial correctness still fails.
- fix-broken-build — the build / terminal-ops axis. Maps to Terminal-Bench 2.0. Tests whether the model uses the failing test suite as a diagnostic tool, or just reads code and guesses.
- review-and-fix-security — the security-judgment axis. OWASP-class vulnerabilities (SQL injection, XSS, hardcoded secret) where each has a canonical fix. Tests whether the model recognizes the pattern and applies the standard mitigation.
Each skill's full definition — task description, seed workspace, pass criteria — is committed in the EvalRig repository alongside the benchmark. Skills are reproducible; a reviewer can re-run any cell.
How the Harness Works
EvalRig is built realism-first. Each evaluation runs in a workspace that looks like a real repository, not a sterile scratchpad:
- Native wire shapes per provider. Anthropic gets
XML-tagged messages, OpenAI gets markdown with JSON fences via the
Responses API, Google gets prose with
system_instructionand typed Parts. Each model sees its own preferred format carrying the same semantic task. Without this, a benchmark silently measures "who handles Anthropic's shape well" instead of capability. - A real repository state. Every workspace is a git
repo with an "initial" commit. Models can run
git log,git blame,git diff— the same tools they use in production. - Ambient project constraints. An
AGENTS.mdfile declares project conventions the model must honor ("parameterized queries only," "no new dependencies," "don't modify tests to make them pass"). Not a Claude-only file — the neutral cross-provider name, specifically chosen to avoid provider bias. - Realistic distractors. Unrelated TODO comments, a
stale README "roadmap" section, a
test_legacy.pywith skipped tests for blocked work. Forces the model to target the right fix, not pattern-match on "something's broken." - Iterative tool loop. Two MCP servers
(Model Context Protocol, the same spec Claude Code and OpenAI's
Codex CLI use): one filesystem server for read/write/edit, and a
sandboxed shell server that lets the model run
bash run_tests.sh, read failures, and iterate. Up to 15 tool rounds per run.
Three-layer evaluation
Each output is scored through three independent layers:
- Tool-efficiency rule — bounded reward for completing the task in a reasonable number of rounds with a reasonable tool-error rate. Weighted 20%.
- Outcome assertions — most significantly,
script_passesonbash run_tests.sh. If the model's edit doesn't make the test suite green, it doesn't pass. Weighted 55%. - Ensemble LLM judge with provider recusal: Claude Opus, GPT-5.4, and Gemini 3.1 Pro each score independently, but never their own provider's outputs. When judging an Opus output, only GPT and Gemini judge. Scores combined via median (robust to a single judge failure). Weighted 25%.
This three-layer approach means: rules catch inefficient iteration,
script_passes catches incorrect fixes, and the judge
catches semantic quality issues. No single layer can inflate a score,
and no model can grade itself.
The Tool-Round Ceiling — A Methodological Save
In the original run (April 18, 2026), GPT-5.4 appeared to fail catastrophically on two skills: 0.65 on fix-cross-file-bug (σ=0.56) and 0.30 on fix-concurrency-bug (σ=0.52). If we had published those numbers, the headline would have read "GPT-5.4 fails agentic debugging."
The pre-registration saved us. Section 5 of our committed pre-reg contains this decision rule:
Stddev > 0.20 on any cell — explicitly refuse to report a mean for that cell; show distribution only.
Both of GPT-5.4's "failing" cells met that threshold. When we
inspected the distribution, the scores were bimodal, not
noisy: runs were either 0.90+ (passing cleanly) or 0.0
(total failure). The failing runs had one thing in common —
tool_rounds=15, hitting our configured ceiling, with
output_length=0, meaning the model was cut off
mid-exploration before producing a final answer.
Opus and Gemini never approached the ceiling: their maximum observed tool rounds across all 45 cells was 13. Only GPT-5.4 hit 15.
We re-ran the two affected GPT-5.4 cells at a 25-round ceiling
(exposed via a new EVALRIG_MAX_TOOL_ROUNDS env-var
override). Results:
| Cell | Ceiling = 15 | Ceiling = 25 | Rounds used |
|---|---|---|---|
| fix-cross-file-bug | 0.65 FAIL (σ=0.56) | 0.91 PASS (σ=0.02) | 9, 14, 11 |
| fix-concurrency-bug | 0.30 FAIL (σ=0.52) | 0.80 PASS (σ=0.01) | 22, 18, 13 |
At the higher ceiling, GPT-5.4 completes both tasks at quality comparable to the other models. The "failures" were a harness artifact, not a capability gap.
What we kept, and what we changed: the ceiling=25 numbers are used for GPT-5.4 on those two cells specifically. All other 13 cells are unchanged — neither Opus nor Gemini ever came close to the original ceiling, so their ceiling=15 data is equivalent to ceiling=25 data. This is a per-cell fairness fix, not a global methodology change.
What remains a real finding: GPT-5.4 genuinely uses more tool rounds than Opus or Gemini on concurrency work. Even at the higher ceiling, individual runs used up to 22 rounds. That's a legitimate efficiency cost — mean of 17.7 rounds versus 10.7 for Opus and 10.3 for Gemini, roughly 1.65-1.72× their round count on this skill — and we report it alongside the quality score rather than burying it.
The full provenance is in pre-registration Addendum C, committed alongside the remediation. Every deviation from the original plan is disclosed by name.
Full Results
| Model | Avg Score | Pass Rate | Total Cost | Avg Tokens |
|---|---|---|---|---|
| Claude Opus 4.7 | 0.979 | 5/5 | $10.33 | — |
| Gemini 3.1 Pro | 0.952 | 5/5 | $2.98 | — |
| GPT-5.4 | 0.934 | 5/5 | $5.24 | — |
Skill-by-skill breakdown
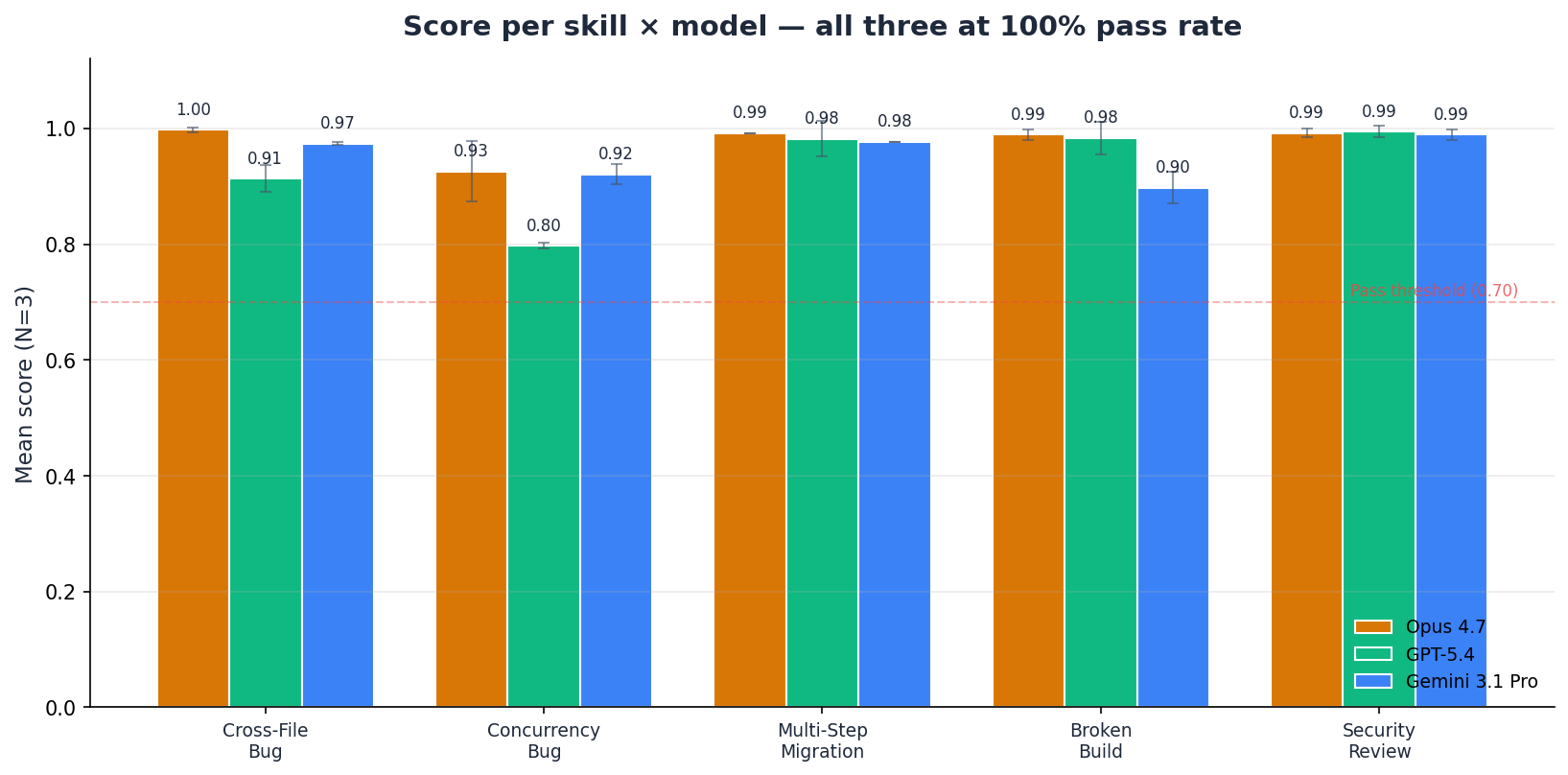
| Skill | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| Fix Cross-File Bug | 1.00 | 0.91 | 0.97 |
| Fix Concurrency Bug | 0.93 | 0.80 | 0.92 |
| Multi-Step Migration | 0.99 | 0.98 | 0.98 |
| Fix Broken Build | 0.99 | 0.98 | 0.90 |
| Review & Fix Security | 0.99 | 0.99 | 0.99 |
Five patterns stand out.
First, Opus 4.7 is the top-scoring model on four of five skills. The fifth (review-and-fix-security) is a 2-dp tie: at 3-decimal precision, GPT-5.4 edges Opus 0.994 vs 0.992 — a 0.002 gap well inside noise. If your workflow cannot tolerate a miss, Opus is the safe default, at roughly 2× GPT-5.4's cost and 3.5× Gemini's.
Second, Gemini 3.1 Pro is the value leader and stays close to Opus. 0.952 average at $2.98 total across 45 invocations. Against GPT-5.4, Gemini wins two skills (cross-file bug, concurrency bug) and essentially ties two more (migration and security, within 0.005). Against Opus, Gemini is within 0.03 on every skill except fix-broken-build (where it lands at 0.90 — still passing, just not flagship-level).
Third, GPT-5.4 is consistent once given enough rounds. Post-ceiling-correction it passes every cell. Averages 0.934 at $5.24, middle on cost but slightly behind Gemini on quality (Opus 0.979 > Gemini 0.952 > GPT 0.934). Its weakness is tool-round consumption, not capability.
Fourth, skill difficulty varies less than expected at the frontier tier. Four of five skills have all three models within 0.10 of each other (ranges: 0.08, 0.02, 0.09, 0.01 respectively). Only fix-concurrency-bug (range 0.13, driven by GPT-5.4 at 0.80 vs Opus/Gemini at 0.92-0.93) shows a spread above 0.10.
Fifth, fix-broken-build is the only skill where GPT-5.4 decisively beats Gemini. GPT-5.4 at 0.98 versus Gemini at 0.90 is a 0.085 gap — the widest margin GPT holds over Gemini on any skill. Build / terminal-ops work may be a specific GPT-5.4 advantage worth reproducing in a future benchmark.
Tool Efficiency — The Hidden Story
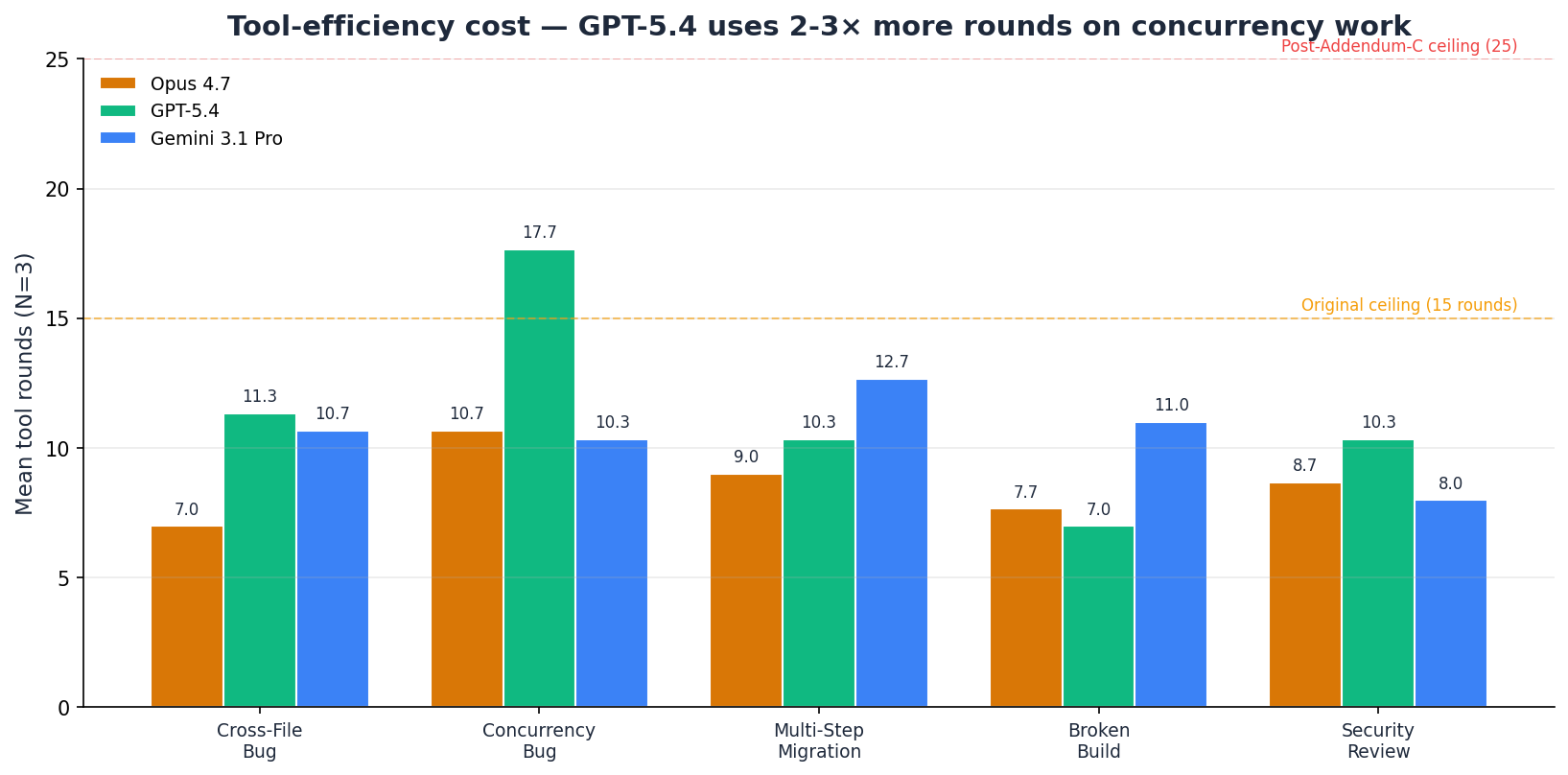
The quality-score table shows all three models at 100% pass rate. The
tool-rounds table shows they are not equivalent in how they achieve
it. GPT-5.4 uses roughly 1.65-1.72× more rounds on
fix-concurrency-bug (17.7 mean vs 10.7 for Opus and 10.3
for Gemini), with individual runs peaking at 22.
Why this matters commercially. Each tool round is an additional API call. More rounds means more tokens sent, more tokens produced, and more latency. For real-time workflows — where an agent is running against customer-facing infrastructure — GPT-5.4's 17.7-round mean on concurrency bugs translates to materially higher per-incident cost than Opus's 10.7-round or Gemini's 10.3-round mean.
Why this matters for benchmark authors. Any benchmark with a low tool-round ceiling will produce artefact "failures" for models that legitimately need more iteration space. Our 15-round cap originally caught GPT-5.4 twice; after the Addendum-C correction, the fair ceiling for this corpus is 25. Future EvalRig benchmarks will use 25 as the standard ceiling and disclose per-cell round counts as a separate metric.
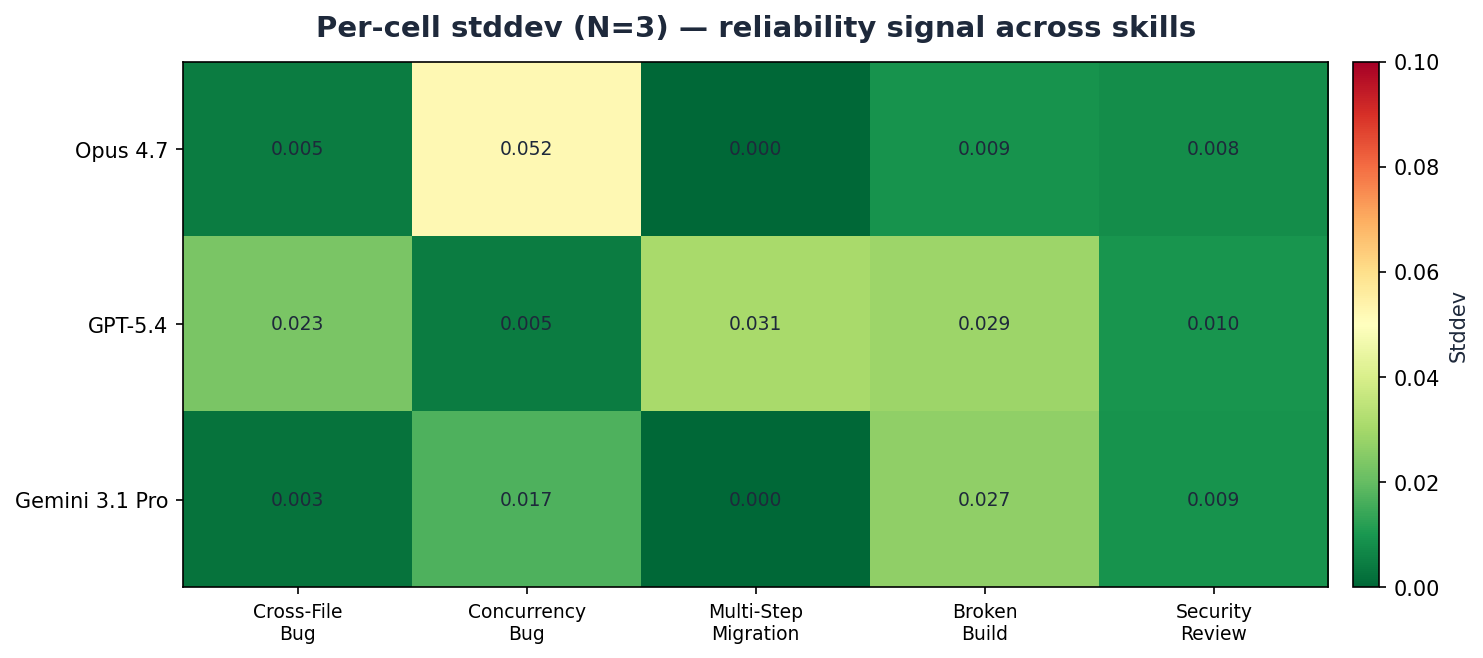
Low stddev across the board signals reliable models and a stable harness. The one cell just above 0.05 is Opus on fix-concurrency-bug at σ=0.052 — a narrow band where Opus landed runs at 0.87, 0.94, and 0.97, still all well above the pass threshold. Historical outliers from the original run (Gemini quota-exhausted cells, GPT-5.4 ceiling-hit cells) have been replaced by the surgical re-run data, so the heatmap reflects clean N=3 stddev on every cell.
Cost Efficiency — Four Metrics, Not One
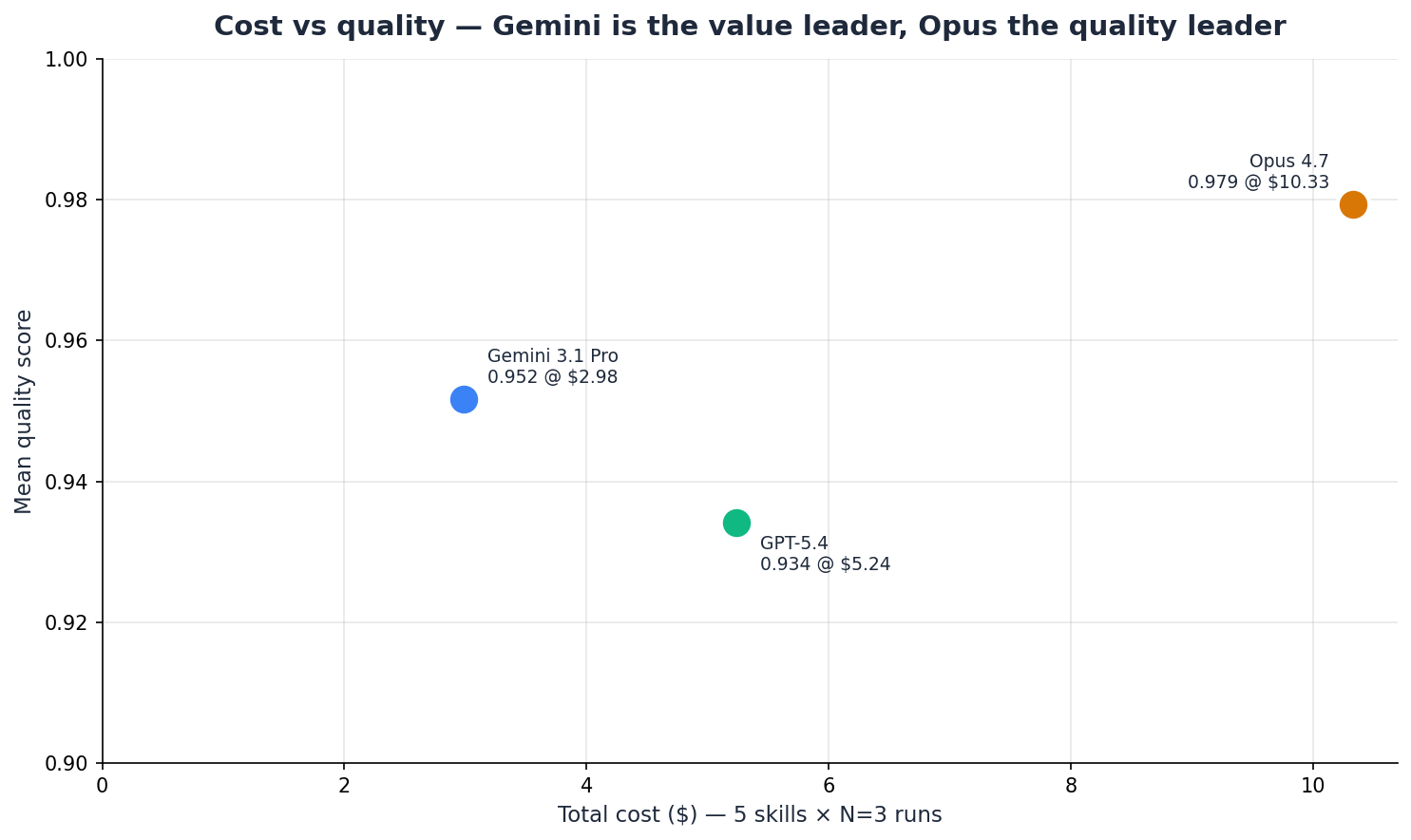
| Model | Tier | Avg Score | Total Cost | Cost / Quality Pt |
|---|---|---|---|---|
| Gemini 3.1 Pro | Flagship | 0.952 | $2.98 | $3.13 |
| GPT-5.4 | Flagship | 0.934 | $5.24 | $5.61 |
| Claude Opus 4.7 | Flagship | 0.979 | $10.33 | $10.55 |
A single cost-per-quality-point number silently hides the tokenizer asymmetry confound: the same English text tokenizes into different token counts for each provider, so USD-per-token rankings reward whichever tokenizer packs more efficiently, independent of model capability. We disclose four cost metrics so readers can see which rankings are robust across normalizations:
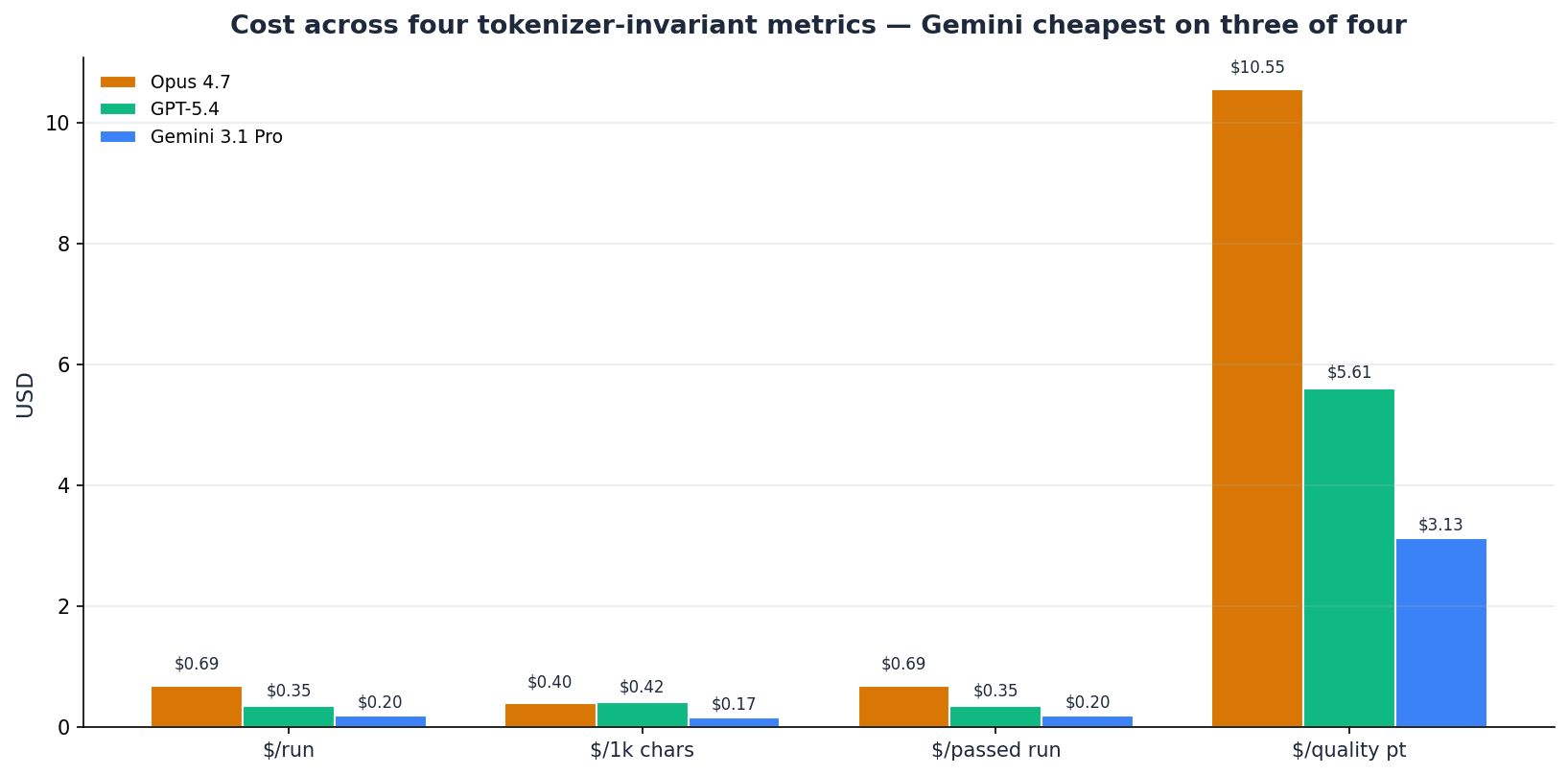
Gemini is cheapest on all four metrics ($/run $0.20, $/1k output chars $0.17, $/passed run $0.20, $/quality pt $3.13). This is a robust finding — whichever way you normalize cost, Gemini wins the efficiency ranking. On $/1k output chars specifically, Opus ($0.40) is actually cheaper than GPT-5.4 ($0.42) — a reminder that per-character economics can flip the per-token ranking.
Opus's premium buys you the highest-quality output. At $10.33 for the full benchmark, it costs 3.5× Gemini and 2× GPT-5.4 for an additional 0.03-0.05 in average quality (0.027 over Gemini, 0.045 over GPT-5.4). Whether that premium is justified depends entirely on your workflow's error tolerance.
A caveat on these rankings: cost efficiency rewards cheap-and-adequate over expensive-and-excellent. Gemini's 0.90 on fix-broken-build is an 8-point drop from GPT-5.4's 0.98 on the same skill. If build-fix reliability is your team's critical path, the cheapest-per-QP number would steer you wrong. Always read cost efficiency alongside the per-skill table.
Recommendation Matrix — Picking by Skill
For each skill, the model to pick depends on whether you're optimizing for quality, cost, or balance. This is the consulting takeaway: a one-size-fits-all headline hides the per-skill nuance.
| Skill | Best Quality | Best Value | Notes |
|---|---|---|---|
| Fix Cross-File Bug | Opus 4.7 (1.00) | Gemini 3.1 Pro (0.97) | Gemini within 0.03 at ~29% of Opus cost. |
| Fix Concurrency Bug | Opus 4.7 (0.93) | Gemini 3.1 Pro (0.92) | Gemini essentially ties Opus; GPT-5.4 at 0.80 uses 1.7× more tool rounds. |
| Multi-Step Migration | Opus 4.7 (0.99) | Gemini or GPT (0.98) | Three-way within 0.02. Pick by cost. |
| Fix Broken Build | Opus 4.7 (0.99) | GPT-5.4 (0.98) | Opus narrowly leads GPT (0.99 vs 0.98). Gemini lags at 0.90. |
| Review & Fix Security | Three-way tie (0.99) | Gemini 3.1 Pro (0.99) | Identical at 2-dp; pick cheapest. |
Two of five skills are essentially three-way ties at the top (multi-step-migration within 0.02, review-and-fix-security within 0.005). For those skills, the right question is cost, not quality — and Gemini wins. On fix-concurrency-bug, Opus and Gemini are functionally tied (0.926 vs 0.921) while GPT-5.4 uses roughly 1.7× the tool rounds. On fix-broken-build, Opus narrowly leads GPT-5.4 (0.99 vs 0.98) while Gemini lags by 0.085. On fix-cross-file-bug, Opus's 1.00 is the only meaningful lead.
What This Means
The question for engineering leaders isn't which frontier model is best. The data answers that: Opus for quality, Gemini for value, GPT-5.4 for a specific subset including build-ops. The question is whether your team's model-selection decision is being made with benchmark data or with whatever the sales team's demo used.
If you need reliable code-fix output on varied task types and cost is secondary, Opus 4.7 is the defensible default. 5/5 pass rate, highest quality on every cell, lowest variance. You pay 3.5× more than Gemini for roughly 0.02-0.05 of additional average quality — a small premium if your workflow cannot tolerate misses.
If you're cost-sensitive and can tolerate occasional 0.90 instead of 1.00, Gemini 3.1 Pro is the clear pick. Against GPT-5.4, Gemini wins or essentially ties on four of five skills. At 29% of Opus's cost and 57% of GPT-5.4's, Gemini is the only model in this benchmark that is simultaneously in the top two on quality and the absolute cheapest on every cost metric.
If your workload is specifically build / terminal-ops heavy, GPT-5.4 at 0.98 on fix-broken-build is the right pick — Gemini lags noticeably here (0.90) and Opus costs more without a meaningful quality advantage. Watch the tool-round consumption on concurrency work, which runs materially higher than competitors.
One more observation that may be underweighted in the public discourse: the top three frontier models are functionally equivalent on four out of five skills at the flagship tier. The days of "GPT-5 fails where Opus wins" or vice versa are essentially over at the task difficulty this benchmark measures. Selection is now a cost-and-workflow question, not a capability question.
Limitations
We disclose these above the headline numbers, not in a footnote.
- N=3 limits statistical resolution. Per-cell stddev averages ~0.015 post-correction (max 0.052 on Opus × fix-concurrency-bug), giving a 95% CI half-width of roughly ±0.04 per cell. Gaps under 0.04 on mean scores (e.g., Gemini 0.952 vs GPT-5.4 0.934 at 0.018) are within noise at N=3. A follow-up run at N=10 would tighten the CI to roughly ±0.02. We cite this in every directional claim.
- Tokenizer cost differences. The same English text tokenizes into different token counts for each provider. USD costs silently fold that asymmetry into the ranking. We disclose four cost metrics (including character-based normalization) to make the confound visible; readers should verify a cost ranking holds across all four before acting on it.
- Training-data overlap is not controllable. Models trained on more Claude-flavored instruction-tuning data retain an advantage even on per-provider native-rendered prompts. We cannot neutralize this from the harness side; we name it upfront and disclose it.
- AGENTS.md authorship confound. The ambient
project-context files in our workspace seeds are hand-authored.
Word choices ("prefer
str | None," "parameterized queries only") could favor whichever provider's training distribution leans that way. We pattern-audit for wire-shape leakage viascripts/audit_skill_neutrality.py, but empirical content-bias audit requires human-graded calibration — a separate open workstream we have designed but not yet executed. - Single-grader calibration is still pending. Our
ensemble judge with cross-provider recusal is the first-order
defense against LLM-grading-LLM bias. Human-graded calibration
would measure how closely judge scores track human judgment —
currently unmeasured. Planned as the next methodology investment;
see
docs/human_graded_calibration.mdin the EvalRig repository. - Five skills is a specific cut of a larger capability space. Different choices could rearrange the ranking. This benchmark measures agentic coding with iterative test feedback on these specific skills — not "general AI capability" or "which model is best." A follow-up hallucination benchmark, a long-horizon multi-session benchmark, and an ambient-org-context benchmark are all on the EvalRig roadmap.
- The tool-round ceiling discovery shows a kind of result-sensitivity we will guard against. Our pre-reg's distribution-over-mean decision rule caught the ceiling effect; without it we'd have published misleading GPT-5.4 numbers. We document the Addendum-C correction in full; future benchmarks will default to a 25-round ceiling with similar distribution checks baked in.